
[정보처리기사 실기] 8장 요약 키워드 정리 _ SQL 응용
딱지의겨울
·2021. 4. 16. 11:42
[8] SQL 응용
8.1 SQL - DDL
DDL(데이터 정의어)의 개념
- 데이터 베이스의 구조를 정의 및 변경하는 언어.
- DDL은 번역한 결과가 데이터 사전이라는 특별한 파일에 여러 개의 테이블로서 저장됨.
- 종류: CREATE, ALTER, DROP
CREATE SCHEMA
- 스키마를 정의하는 명령문.
- 스키마: 데이터베이스의 구조와 제약 조건에 관한 전반적인 명세를 기술한 것으로 데이터 개체, 속성, 관계 및 데이터 조작시 데이터 값들이 갖는 제약 조건 등에 관해 전반적으로 정의 함.
- 스키마의 식별을 위해 스키마 이름과 소유권자나 허가권자를 정의함.
- 표기 형식
|
CREATE SCHEMA 스키마명 AUTHORIZATION 사용자_id; |
CREATE DOMAIN
- 도메인을 정의하는 명령문.
- 도메인: 하나의 속성이 취할 수 있는 동일한 유형의 원자값들의 집합. 특정 속성에서 사용할 데이터의 범위를 사용자가 정의하는 사용자 정의 데이터 타입.
- 임의의 속성에서 취할 수 있는 값의 범위가 SQL에서 지원하는 전체 데이터 타입의 값이 아니고 일부분일 때, 그 값의 범위를 도메인으로 정의할 수 있음.
- 정의된 도메인명은 일반적인 데이터 타입처럼 사용함.
- 표기 형식
|
CREATE DOMAIN [도메인명] AS 데이터_타입 |
- 데이터 타입: SQL 에서 지원하는 데이터 타입
- 기본값: 데이터를 입력하지 않았을 때 자동으로 입력되는 값.
(예) ‘성별’을 ‘남’, ‘여’의 1개의 문자로 표현하는 도매인 SQL
|
CREATE DOMAIN SEX AS CHAR(1) |
SQL 기본 데이터 타입
- 정수: INTEGER(4Byte), SMALLINT(2Byte)
- 실수: FLOAT, REAL, DOUBLE PRECISION
- 형식화된 문자: DEC(i, j) i: 전체 자릿수, j: 소수부 자릿수
- 고정 길이 문자: CHAR(n), CHARACTER(n) n:문자수
- 가변 길이 문자: VARCHAR(n), CHARACTER VARYING(n) n: 최대 문자수
- 고정 길이 비트열: BIT(n)
- 가변 길이 비트열: VARBIT(n)
- 날짜: DATE
- 시간: TIME
CREATE TABLE
- 테이블을 정의하는 명령문.
- 테이블: 데이터베이스의 설계 단계에서는 릴레이션이라고 부르고, 조작 검색 시는 테이블이라고 부름.
- 표기 형식
|
CREATE TABLE 테이블명 (속성명 데이터_타입[DEFAULT 기본값][NOT NULL], … [, PRIMARY KEY(기본키_속성명)] [, UNIQUE(대체키_속성명)] [, FOREIGN KEY(외래키_속성명)] REFERENCES 참조테이블(기본키_속성명, ... )] [ON DELETE 옵션] [ON UPDATE 옵션] [, CONSTRAINT 제약조건명][CHECK (조건식)]); |
- 기본 테이블에 포함될 모든 속성에 대하여 그 속성명과 그 속성의 데이터 타입, 기본값, NOT NULL 여부를 지정함.
- PRIMARY KEY: 기본키로 사용될 속성
- UNIQUE: 대체키로 사용될 속성을 지정하는 것으로 중복된 값을 가질 수 없음.
- FOREIGN KEY ~ REFERENCES ~
- 참조할 다른 테이블과 그 테이블을 참조할 때 사용할 외래 키 속성을 지정.
- 외래키가 지정되면 참조 무결성의 CASCADE 법칙(참조 무결성 제약이 설정된 기본테이블의 어떤 데이터를 삭제할 경우 그 데이터와 밀접하게 연관되어 있는 다른 테이블의 데이터들도 도미노식으로 자동으로 삭제됨.)이 적용됨.
- ON DELETE 옵션: 참조 테이블의 튜플이 삭제되었을 때 기본 테이블에 취해야 할 사항을 지정함. (NO ACTION, CASCADE, SET NULL, SET DEFAULT)
- ON UPDATE 옵션: 참조 테이블의 참조 속성 값이 변경되었을 때 기본 테이블에 취해야 할 사항을 지정함.
- NO ACTION: 참조 테이블에 변화가 있어도 기본 테이블에는 아무런 조취를 취하지 않음.
- CASCADE: 참조 테이블의 튜플이 삭제되면 기본 테이블의 관련 튜플도 모두 삭제되고, 속성이 변경되면 관련 튜플의 속성값도 모두 변경됨.
- SET NULL: 참조 테이블에 변화가 있으면 기본 테이블의 속성값을 NULL로 변경함.
- SET DEFAULT: 참조 테이블에 변화가 있으면 기본테이블의 관련 튜플의 속성 값을 기본값으로 변경함.
- CONSTRAINT: 제약조건의 이름을 지정함. 이름을 지정할 필요가 없으면 check 절만 사용하여 속성값에 대한 제약 조건을 명시함.
- CHECK: 속성에 대한 제약 조건을 정의
(예) ‘이름’, ‘학번’, ‘전공’, ‘성별’, ‘생년월일’로 구성된 <학생> 테이블을 정의.
- ‘이름’은 NULL 이 올수 없고 , ‘학번’은 기본키.
- ‘전공’은 <학과> 테이블의 ‘학과코드’를 참조하는 외래키로 사용.
- <학과> 테이블에서 삭제가 일어나면 관련 튜플들의 전공값을 NULL로 만든다.
- <학과> 테이블에서 ‘학과코드’가 변경되면 전공 값도 같은 값으로 변경
- ‘생년월일’은 1980-01-01 이후의 데이터만 저장.
- 제약조건의 이름은 ‘생년월일제약’
- 각 속성의 데이터 타입은 적당하게 지정. 단 ‘성별’은 도메인 ‘SEX’ 사용.
|
CREATE TABLE 학생 |
- 다른 테이블을 이용한 테이블 정의
|
CREATE TABLE 신규테이블명 AS SELECT 속성명, … FROM 기존테이블명; |
- 기존 테이블의 추출되는 속성 데이터 타입, NOT NULL 정의는 그대로 적용.
- 기존 테이블의 제약 조건은 신규 테이블에 적용되지 않으므로 신규 테이블을 정의한 후 ALTER TABLE 명령을 이용해 제약조건을 추가해야 함.
- 기존 테이블의 모든 속성을 신규 테이블로 생성할 때는 속성명 부분어 ‘*’를 입력
|
CREATE TABLE 재학생 AS SELECT 학번, 이름, 학년 FROM 학생; |
CREATE VIEW
- 뷰를 정의하는 명령문.
- 뷰: 물리적으로 구현되지는 않지만 뷰 정의가 시스템 내에 정의되어 있다가 뷰 이름을 사용하면 실행 시간에 뷰 정의가 대체되어 수행됨.
- 표기 형식
|
CREATE VIEW 뷰명[(속성명, ... )] AS SELECT문; |
- SELECT 문을 서브 쿼리로 사용하여 SELECT문의 결과로서 뷰를 생성.
- 서브쿼리인 SELECT문에는 UNION, ORDER BY 절을 사용할 수 없음.
- 속성 명을 기술하지 않으면 SELECT 문의 속성명이 자동으로 사용됨.
(예) <고객> 테이블에서 ‘주소’가 ‘안산시’인 고객들의 ‘성명’과 ‘전화번호’를 ‘안산고객’이라는 뷰로 정의.
|
CREATE VIEW 안산고객 AS SELECT 성명, 전화번호 FROM 고객 WHERE 주소 = ‘안산시’; |
CREATE INDEX
- 인덱스를 정의하는 명령문.
- 인덱스: 검색 시간을 단축시키기 위해 만든 보조적인 데이터 구조.
- 표기 형식
|
CREATE [UNIQUE] INDEX 인덱스명 ON 테이블명(속성명[ASC | DESC] , … ) [CLUSTER]; |
- UNIQUE
- 사용된 경우: 중복값이 없는 속성으로 생성
- 생략된 경우: 종복값 허용
- 정렬 여부 지정
- ASC: 오름차순 정렬
- DESC: 내림차순 정렬
- 생략된 경우: 오름차순으로 정렬됨
- CLUSTER: 사용하면 클러스터드 인덱스(인덱스 키 순서에 따라 데이터가 정렬되어 저장되는 방식. 실제 데이터가 순서대로 저장되어 있어 인덱스를 검색하지 않아도 빠르게 찾을 수 있지만, 데이터 삽입, 삭제 발생시 재정렬해야 함)로 설정.
(예) <고객> 테이블에서 UNIQUE 한 특성을 갖는 ‘고객번호’ 속성에 대해 내림차순으로 정렬하여 ‘고객번호_idx’라는 이름의 인덱스 정의.
|
CREATE UNIQUE INDEX 고객번호_idx ON 고객(고객번호 DESC); |
ALTER TABLE
- 테이블에 대한 정의를 변경하는 명령분.
- 표기 형식
|
ALTER TABLE 테이블명 ADD 속성명 데이터타입[DEFAULT ‘기본값’]; |
(예) <학생> 테이블에 최대 3문자로 구성되는 ‘학년’ 속성 추가.
|
ALTER TABLE 학생 ADD 학년 VARCHAR(3); |
(예) <학생> 테이블의 ‘학번’ 필드의 데이터 타입과 크기를 VARCHAR(10)으로 하고 NULL 값이 입력되지 않도록 변경
|
ALTER TABLE 학생 ALTER 학번 VARCHAR(10) NOT NULL; |
DROP
- 스키마, 도메인, 기본 테이블, 뷰 테이블, 인덱스, 제약 조건 등을 제거하는 명령문
- 표기형식
|
DROP SCHEMA 스키마명 [CASCADE | RESTRICTED]; DROP DOMAIN 도메인명 [CASCADE | RESTRICTED]; DROP TABLE 테이블명 [CASCADE | RESTRICTED]; DROP VIEW 뷰명 [CASCADE | RESTRICTED]; DROP INDEX 인덱스명 [CASCADE | RESTRICTED]; DROP CONSTRAINT 제약조건명; |
- CASCADE: 제거할 요소를 참조하는 다른 모든 개체를 함께 제거. 주 테이블의 데이터 제거시 각 외래키와 관계를 맺고 있는 모든 데이터를 제거하는 참조 무결성 제약 조건을 설정하기 위해 사용.
- RESTRICTED: 다른 개체가 제거할 요소를 참조중일 때는 제거를 취소.
8.2 SQL - DCL
DCL(데이터 제어어)의 개념
- 데이터의 보안, 무결성, 회복, 병행 제어 등을 정의하는데 사용하는 언어.
- 데이터베이스 관리자(DBA)가 데이터 관리를 목적으로 사용함.
- 종류: GRANT, REVOKE, COMMIT, ROLLBACK, SAVEPOINT
GRANT/REVOKE
- 데이터베이스 관리자가 데이터베이스 사용자에게 권한을 부여하거나 취소하기 위한 명령어.
- GRANT: 권한 부여를 위한 명령어
- REVOKE: 권한 취소를 위한 명령어
- 사용자 등급 지정 및 해제
|
GRANT 사용자등급 TO 사용자_ID_리스트 [IDENTIFIED BY 암호]; |
- 사용자 등급
- DBA: 데이터베이스 관리자
- RESOURCE: 데이터베이스 및 테이블 생성 가능자
- CONNECT : 단순 사용자
(예) 사용자 ID가 ‘nabi’ 인 사람에게 데이터베이스 및 테이블을 생성할 수 있는 권한 부여 SQL문
|
GRANT RESOURCES TO nabi; |
- 테이블 및 속성에 대한 권한 부여 및 취소
|
GRANT 권한리스트 ON 테이블및속성 TO 사용자 [WITH GRANT OPTION]; REVOKE [GRANT OPTION FOR] 권한리스트 ON 테이블및속성 FROM 사용자 [CASCADE]; |
- 권한 종류: ALL, SELECT, INSERT, DELETE, UPDATE, ALTER 등
- WITH GRANT OPTION: 부여받은 권한을 다른 사용자에게 다시 부여할 수 있는 권한 부여.
- GRANT OPTION FOR: 다른 사용자에게 권한을 부여할 수 있는 권한을 취소.
- CASCADE: 권한 취소 시 권한을 부여받았던 사용자가 다른 사용자에게 부여한 권한도 연쇄적으로 취소.
(예1) 사용자id가 nabi 인 사람에게 <고객> 테이블에 대한 모든 권한과 다른 사람에게 권한을 부여할 수 있는 권한까지 부여하는 SQL
|
GRANT ALL ON 고객 TO nabi WITH GRANT OPTION; |
(예2) 사용자 아이디가 star인 사람에게 부여한 <고객> 테이블에 대한 권한 중 UPDATE 권한을 다른 사람에게 부여할 수 있는 권한만 취소하는 SQL
|
REVOKE GRANT OPTION FOR UPDATE ON 고객 FROM star; |
COMMIT
- 트랜잭션이 성공적으로 끝나면 데이터베이스가 새로운 일관성 상태를 가지기 위해 변경된 모든 내용을 데이터베이스에 반영할 때 사용하는 명령어.
- 트랜잭션: 데이터베이스에서 하나의 논리적 기능을 수행하기 위한 일련의 연산 집합으로 작업의 단위가 됨. 하나의 트랜잭션은 COMMIT 되거나 ROLLBACK 되어야함.
- 트랜잭션이 시작되면 데이터베이스의 데이터를 주 기억장치에 올려 처리하다가 COMMIT 명령이 내려지면 그때서야 보조기억장치에 저장함. COMMIT을 하지 않고 DBMS를 종료하면 그때까지 작업한 모든 내용이 보조 기억장치의 데이터베이스에 하나도 반영되지 않고 종료됨.
- COMMIT 명령을 실행하지 않아도 DML 문이 성공적으로 완료되면 자동으로 COMMIT 되고, 실패하면 ROLLBACK이 되도록하는 Auto Commit 기능을 설정할 수 있음.
- Auto Commit 설정 명령(MySQL)
- 설정: set autocommit = true;
- 해제: set autocommit = false;
- 확인: select @@autocommit;
(예) <사원> 테이블에서 ‘사원번호’가 40인 사원의 정보를 삭제한 후 COMMIT 수행하시오.
|
DELETE * FROM 사원 WHERE 사원번호 = 40; COMMIT; |
ROLLBACK
- 아직 COMMIT 되지 않은 변경된 모든 내용들을 취소하고 데이터베이스를 이전 상태로 되돌리는 명령어.
- 트랜잭션 전체가 성공적으로 끝나지 않으면 일부 변경된 내용만 데이터베이스에 반영되는 비일관성인 상태를 가질 수 있기 때문에 일부분만 완료된 트랜잭션은 롤백 되어야 함.
SAVEPOINT
- 트랜잭션 내에 ROLLBACK 할 위치인 저장점을 지정하는 명령어.
- 저장점을 지정할 때는 이름을 부여하며, ROLLBACK 시 지정된 저장점까지의 트랜잭션 처리 내용이 취소됨.
(예1) SAVEPOINT S1을 설정하고 사원번호가 20인 사원의 정보를 삭제하시오.
|
SAVEPOINT S1; DELETE * FROM 사원 WHERE 사원번호 = 20; |
(예2) SAVEPOINT S1까지 롤백을 수행하시오.
|
ROLLBACK TO S1; |
(예3) 롤백을 수행하시오.
|
ROLLBACK; |
8.3 SQL - DML
DML(데이터 조작어)의 개념
- 데이터베이스 사용자가 응용 프로그램이나 질의어를 통해 저장된 데이터를 실질적으로 관리하는데 사용되는 언어.
- 데이터베이스 사용자와 DBMS 간의 인터페이스 제공.
- DML의 유형
- SELECT: 테이블에서 튜플 검색
- INSERT: 테이블에 튜플 삽입
- DELETE: 테이블에서 튜플 삭제
- UPDATE: 테이블에서 튜플 내용 갱신
삽입문(INSERT INTO~ VALUES~)
- 기본 테이블에 새로운 튜플 삽입할 때 사용.
- 일반 형식
|
INSERT INTO 테이블명([속성명1, 속성명2, …]) VALUES (데이터1, 데이터2, … ); |
- 대응하는 속성과 데이터는 개수와 데이터 유형이 일치해야 함.
- 기본 테이블의 모든 속성을 사용할때는 속성명을 생략할 수 있음.
- SELECT 문을 사용하여 다른 테이블의 검색 결과를 삽입할 수 있음.
(예1) <사원> 테이블에 이름-홍승현, 부서-인터넷을 삽입.
|
INSERT INTO 사원(이름, 부서) VALUES (홍승현, 인터넷); |
(예2) <사원> 테이블에 있는 모든 편집부의 튜플을 편집부원(이름, 생일, 주소, 기본급) 테이블에 삽입하시오.
|
INSERT INTO 편집부원(이름, 생일, 주소, 기본급) SELECT 이름, 생일, 주소, 기본급 FROM 사원 WHERE 부서 = ‘편집’; |
삭제문(DELETE FROM~)
- 기본 테이블에 있는 튜플들 중에서 특정 튜플(행)을 삭제할 때 사용.
- 일반 형식
|
DELETE FROM 테이블명 [WHERE 조건]; |
- 모든 레코드를 삭제할 때는 WHERE 절을 생략.
- 모든 레코드를 삭제하더라도 테이블 구조는 남아있기 때문에 디스크에서 테이블을 완전히 제거하는 DROP과는 다름.
(예1) <사원> 테이블에서 ‘인터넷’ 부서 모두 삭제
|
DELETE FROM 사원 WHERE 부서 = ‘인터넷’; |
(예2) <사원>의 모든 레코드 삭제
|
DELETE FROM 사원 ; |
갱신문(UPDATE~ SET~)
- 기본 테이블에 있는 튜플들 중에서 특정 튜플의 내용을 변경할 때 사용.
- 일반 형식
|
UPDATE 테이블명 SET 속성명=데이터[, 속성명=데이터, ...] [WHERE 조건]; |
(예1) <사원> 테이블에서 ‘홍길동’의 주소를 ‘수색동’으로 수정하시오.
|
UPDATE 사원 SET 주소 = ‘수색동’ WHERE 이름 = ‘홍길동’; |
(예2) <사원> 테이블에서 ‘황진이’의 부서를 ‘기획부’로 변경하고 ‘기본급’을 5만원 인상하시오.
|
UPDATE 사원 SET 부서 = ‘기획’, 기본급 = 기본급 + 5 WHERE 이름 = ‘황진이’; |
(예3) <학부생> 테이블에서 담당관의 이름이 ‘이’로 시작하는 튜플의 ‘학과번호’를 999로 갱신하시오.
|
UPDATE 학부생 SET 학과번호 = 999 WHERE 담당관 LIKE ‘이%’; |
8.4 DML- SELECT 1
일반 형식
|
SELECT [PREDICATE] 속성명 [AS 별칭][, …] [, 그룹함수(속성명) [AS 별칭]] [, Window 함수 OVER (PARTITION BY 속성명1, 속성명2, …)] FROM 테이블명[, 테이블명, …] [WHERE 조건] [GROUP BY 속성명, 속성명, …] [HAVING 조건] [ORDER BY 속성명 [ASC|DESC]]; |
- SELECT 절
- PREDICATE: 불러올 튜플 수를 제한할 명령어
- ALL: 모든 튜플을 검색할 때 지정하는 것으로 주로 생략함.
- DISTINCT: 중복된 튜플이 있으면 그 중 첫번째 한개만 검색함.
- DISTINCTROW: 중복된 튜플을 제거하고 한 개만 검색하지만 선택된 속성의 값이 아닌 튜플 전체를 대상으로 함.
- 속성명: 검색하여 불러올 속성 또는 속성을 이용한 수식
- 모든 속성을 지정할 때는 * 기술
- 두 개 이상의 테이블을 대상으로 검색할 때는 ‘테이블명.속성명’으로 표현
- AS: 속성 및 연산에 별칭을 붙일때 사용.
- FROM 절: 질의에 의해 검색될 데이터들을 포함하는 테이블명을 기술.
- WHERE 절: 검색할 조건을 기술.
- ORDER BY 절: 특정 속성을 기준으로 정렬하여 검색할 때 사용. ASC > 오름차순, DESC > 내림차순. 생략하면 오름차순으로 지정됨.
조건 연산자 / 연산자 우선순위
- 조건 연산자
- 비교 연산자: =, <>, > , <, <=, >=
- 논리 연산자: NOT, AND, OR
- LIKE 연산자: 대표 문자를 이용해 지정된 속성의 값이 문자 패턴과 일치하는 튜플을 검색하기 위해 사용.
- % : 모든 문자를 대표함
- _ : 문자 하나를 대표함
- # : 숫자 하나를 대표함
- 연산자 우선순위: 산술 > 관계 > 논리
|
산술 연산자 |
x / + - |
|
관계 연산자 |
= > < >= <= <> |
|
논리 연산자 |
NOT AND OR |
기본 검색
(예1) <사원>의 모든 튜플 검색.
|
SELECT * FROM 사원; |
(예2) <사원> 에서 ‘주소’를 검색하되, 같은 ‘주소’는 한 번만 출력하시오.
|
SELECT DISTINCT 주소 FROM 사원; |
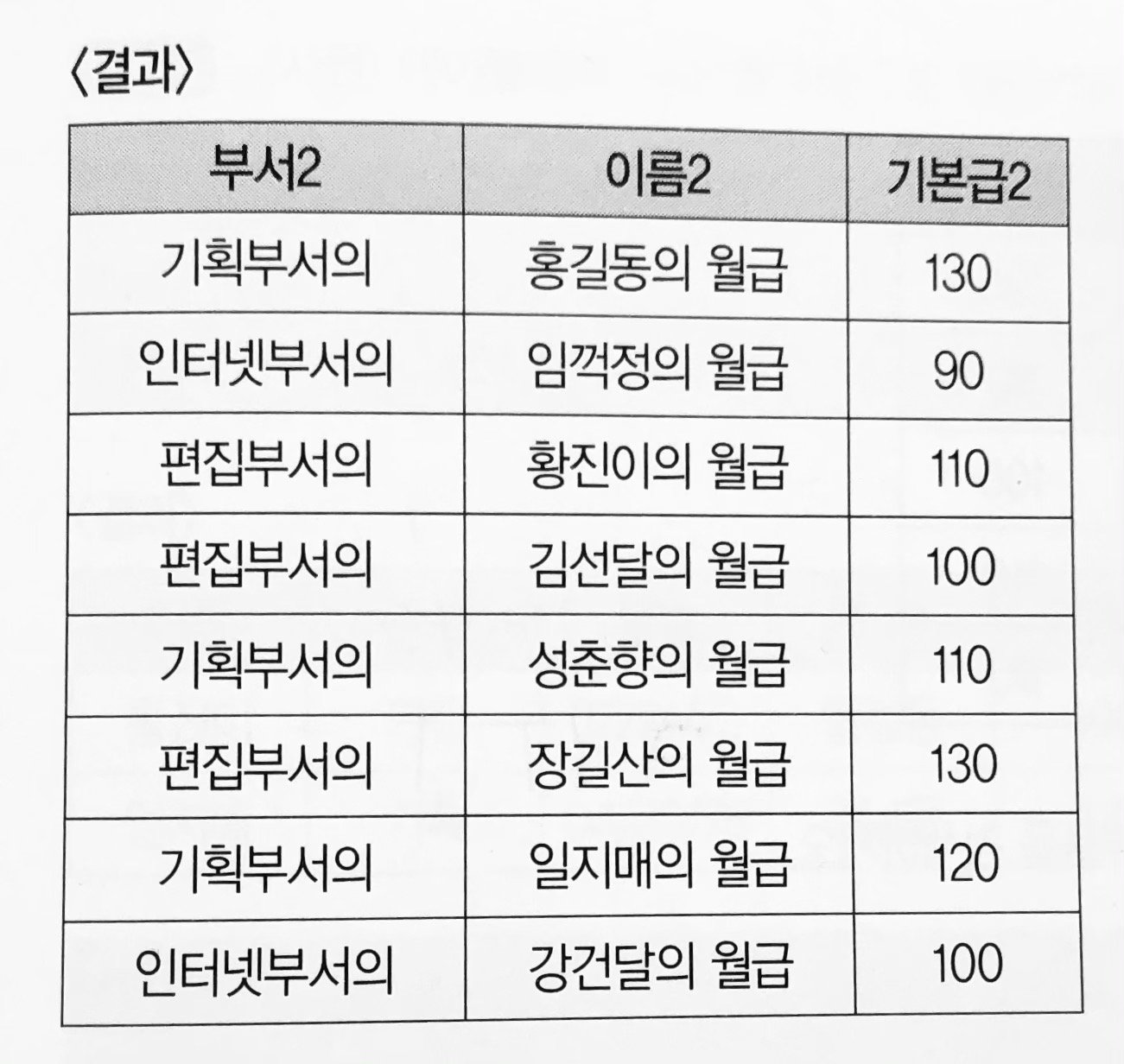
(예3) <사원> 테이블에서 ‘기본급’에 특별 수당 10을 더한 월급을 “xx 부서의 xxx의 월급 xxx” 형태로 출력하시오.
|
SELECT 부서 + ‘부서의’ as 부서2, 이름 + ‘의 월급 ’ as 이름 2,기본급 +10 as 기본급 2 FROM 사원; |
조건 지정 검색(WHERE ~)
(예1) <사원>에서 ‘기획’부의 모든 튜플 검색.
|
SELECT * FROM 사원 WHERE 부서 = ‘기획’; |
(예2) <사원>에서 부서는 ‘기획’이고 기본급이 110보다 큰 튜플 검색.
|
SELECT * FROM 사원 WHERE 부서 = ‘기획’and 기본급 > 110; |
(예3) <사원>에서 부서가 ‘기획’이거나 ‘인터넷’인 튜플 검색
|
SELECT * FROM 사원 WHERE 부서 = ‘기획’ or 부서 = ‘인터넷’; |
(예4) <사원>에 성이 ‘김’인 사람의 튜플 검색
|
SELECT * FROM 사원 WHERE 이름 LIKE “김%”; |
(예5) <사원>에서 생일이 ‘01/01/69’에서 ‘12/31/73’ 사이인 튜플 검색. 날짜는 ‘’ 또는 ## 로 묶어줌.
|
SELECT * FROM 사원 WHERE 생일 BETWEEN #01/01/69# AND #12/31/73#; |
(예6) <사원>에서 ‘주소’가 NULL 인 튜플 검색. IS NULL / IS NOT NULL
|
SELECT * FROM 사원 WHERE 주소 IS NULL; |
정렬 검색(ORDER BY ~)
(예1) <사원>에서 ‘주소’를 기준으로 내림차순 정렬시켜 상위 2개 튜플만 검색하시오.
|
SELECT TOP 2 * FROM 사원 ORDER BY 주소 DESC; |
(예2) <사원>에서 ‘부서’를 기준으로 오름차순 정렬이고, 같은 부서에 대해서는 ‘이름’을 기준으로 내림차순 정렬시켜 검색하시오.
|
SELECT * FROM 사원 ORDER BY 부서 ASC, 이름 DESC; |
하위 질의
- 조건절에 주어진 질의를 먼저 수행하여 그 검색 결과를 조건절의 피연산자로 사용함.
(예1) <사원>에서 취미가 ‘나이트댄스’ 인 사원의 ‘이름’ 과 ‘주소’를 검색하시오.
|
SELECT 이름, 주소 FROM 사원 WHERE 이름 = (SELECT 이름 FROM 여가활동 WHERE 취미 =’나이트댄스’); |
(예2) <사원>에서 취미활동을 하지 않은 사원들을 검색하시오.
|
SELECT 이름 FROM 사원 WHERE 이름 NOT IN (SELECT 이름 FROM 여가활동); |
복수 테이블 검색
(예) ‘경력’이 10년 이상인 사원의 이름, 부서, 취미, 경력 검색.
|
SELECT 사원.이름, 사원.부서, 여가활동.취미, 여가활동.경력 FROM 사원, 여가활동 WHERE 여가활동.경력 >= 10 AND 사원.이름 = 여가활동.이름; |
8.5 DML- SELECT 2
일반 형식
|
SELECT [PREDICATE] 속성명 [AS 별칭][, …] [, 그룹함수(속성명) [AS 별칭]] [, Window함수 OVER (PARTITION BY 속성명1, 속성명2, … ORDER BY 속성명 3, 속성명4, …)[AS 별칭]] FROM 테이블명[, 테이블명, …] [WHERE 조건] [GROUP BY 속성명, 속성명, …] [HAVING 조건] [ORDER BY 속성명 [ASC|DESC]]; |
- 그룹함수: GROUP BY 절에 지정된 그룹별로 속성의 값을 집계할 함수.
- WINDOW 함수: GROUP BY절을 이용하지 않고 속성의 값을 집계할 함수.
- PARTITION BY: WINDOW 함수가 적용될 범위로 사용할 속성 지정.
- ORDER BY: PARTITION 안에서 정렬 기준으로 사용할 속성 지정.
- GROUP BY절: 특정 속성을 기준으로 그룹화하여 검색할 때 사용. 일반적으로 GROUP BY절은 그룹 함수와 함께 사용됨.
- HAVING 절: GROUP BY절의 그룹에 대한 조건 지정.
그룹 함수
- COUNT(속성명): 그룹별 튜플 수
- SUM(속성명): 그룹별 합계
- AVG(속성명): 그룹별 평균
- MAX(속성명): 그룹별 최대값
- MIN(속성명): 그룹별 최소값
- STDDEV(속성명): 그룹별 표준편차
- VARIANCE(속성명): 그룹별 분산
- ROLLUP(속성명, 속성명, …)
- 인수로 주어진 속성을 대상으로 그룹별 소계를 구하는 함수
- 속성의 개수가 n개이면, n+1 레벨까지, 하위 레벨에서 상위레벨 순으로 데이터가 집계됨.
- GROUP BY a, b, c, d 로 묶은 뒤 ROLLUP 을 적용시켜 주면 -> (a, b, c, d) / (a, b, c) / (a, b) / (a) / () 이런식으로 그룹을 만들어가며 집계를 낸다.
- CUBE(속성명, 속성명, …)
- ROLLUP과 유사한 형태이나 CUBE는 인수로 주어진 속성을 대상으로 모든 조합의 그룹별 소계를 구함.
- 속성의 개수가 n개이면 n^2레벨까지, 상위 레벨부터 하위레벨 순으로 데이터 집계 됨.
- ROLLUP (a, b, c) : (a, b, c) / (a, b) / (a) / ()
- CUBE (a, b, c) : (a, b, c) / (a, b) / (a, c) / (b, c) / (a) / (b) / (c) / ()
WINDOW 함수
- GROUP BY절을 이용하지 않고 함수의 인수로 지정한 속성을 범위로 하여 속성의 값을 집계함.
- 함수의 인수로 지정한 속성이 대상 레코드의 범위가 되는데, 이를 윈도우라고 부름.
- 종류
- ROW_NUMBER(): 윈도우별로 각 레코드에 대한 일련번호 반환.
- RANK(): 윈도우별 순위 반환하며 공동순위 반영.
- DENSE_RANK(): 윈도우별 순위 반환하며, 공동순위 무시.
WINDOW 함수 이용 검색
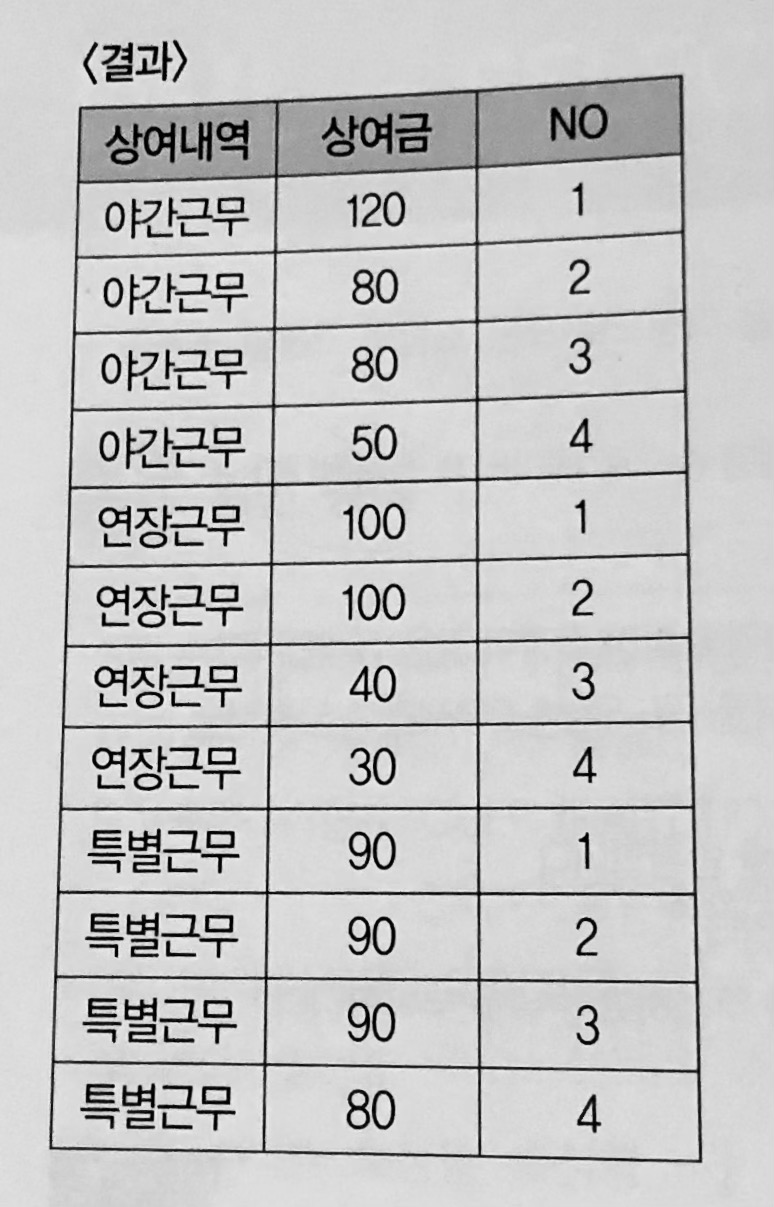
(예1) <상여금> 테이블에서 ‘상여내역’별로 ‘상여금’에 대한 일련번호를 구하시오.(순서는 내림차순이며, 속성명은 ‘NO’로 할 것)
|
SELECT 상여내역, 상여금 ROW_NUMBER OVER (PARTITION BY 상여내역 ORDER BY 상여금 DESC) AS NO FROM 상여금; |
(예2) <상여금> 테이블에서 ‘상여내역’별로 ‘상여금’에 대한 순위를 구하시오. (순서는 내림차순이며, 속성명은 ‘상여금순위’로 하고 RANK() 함수를 이용할 것)
|
SELECT 상여 내역, 상여금, RANK() OVER(PARTITION BY 상여내역 ORDER BY 상여금 DESC) AS 상여금순위 FROM 상여금; |

그룹 지정 검색
(예1) <상여금>에서 ‘부서’별 ‘상여금’의 평균 구하시오.
|
SELECT 부서, AVG(상여금) AS 평균 FROM 상여금 GROUP BY 부서; |
(예2) <상여금>에서 ‘부서’별 튜플 수를 검색하시오.
|
SELECT 부서, COUNT(*) AS 사원수 FROM 상여금 GROUP BY 부서; |
(예3) <상여금>에서 상여금이 100이상인 사원이 2명 이상인 ‘부서’의 튜플 수를 구하시오.
|
SELECT 부서, COUNT(*) AS ‘사원수’ FROM 상여금 WHERE 상여금 >= 100 //상여금 100 이상 검색 GROUP BY 부서 //상여금이 100 이상인 자료에 대해서만 부서별로 그룹 지정 HAVING COUNT(*) >= 2; // 부서의 인원이 2 이상 |
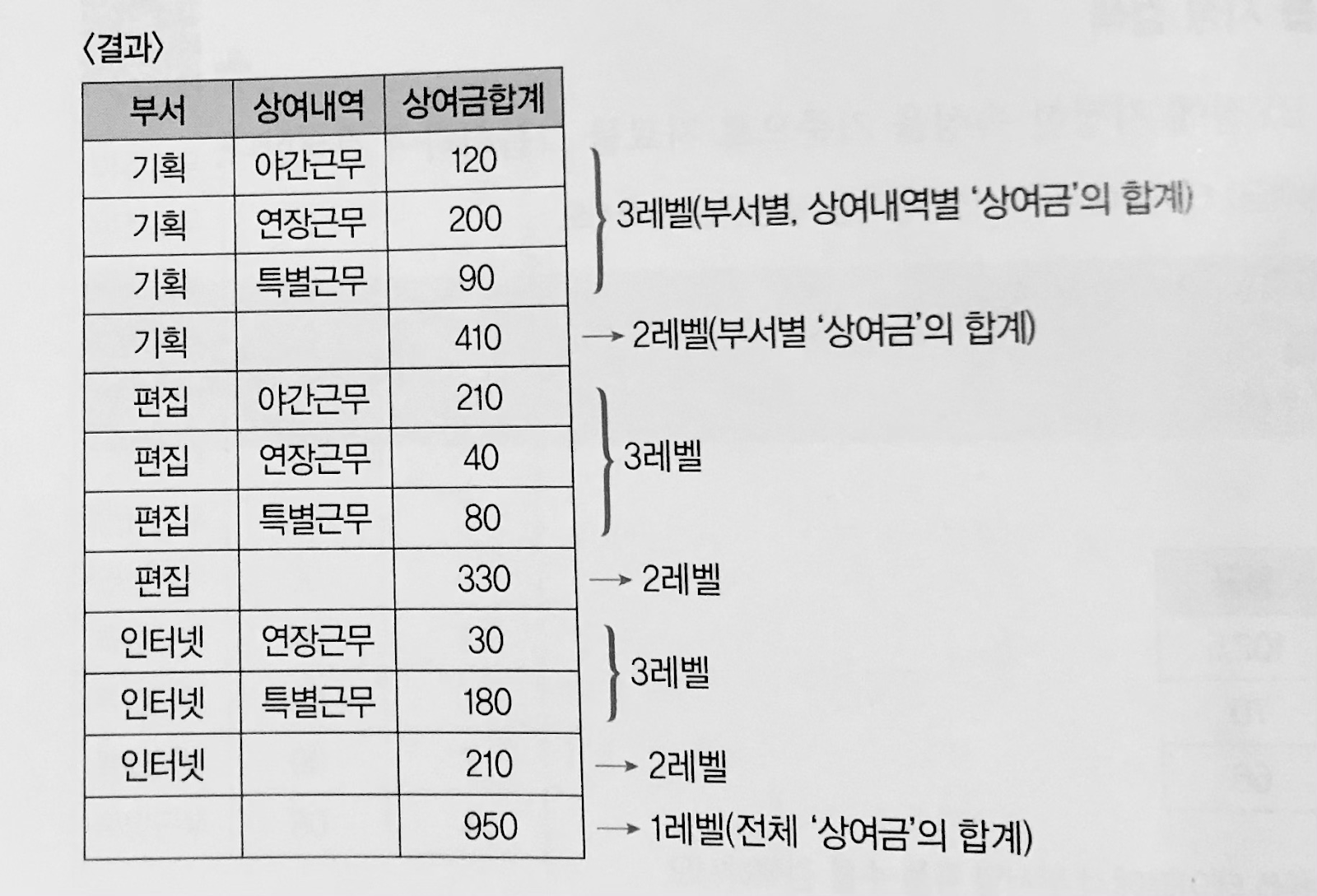
(예4) <상여금>에서 ‘부서’, ‘상여내역’, 그리고 ‘상여금’에 대해 부서별 상여내역별 소계와 전체합계를 검색하시오. (속성명은 ‘상여금합계’, ROLLUP 함수를 사용할 것)
|
SELECT 부서, 상여내역, SUM(상여금) AS 상여금합계 FROM 상여금 GROUP BY ROLLUP(부서, 상여내역); |
(예5) <상여금>에서 ‘부서’, ‘상여내역’, 그리고 ‘상여금’에 대해 부서별 상여내역별 소계와 전체 합계를 검색하시오. (속성명은 ‘상여금합계, CUBE함수를 사용할 것)
|
SELECT 부서, 상여내역, SUM(상여금) AS 상여금합계 FROM 상여금 GROUP BY CUBE(부서, 상여내역); |

8.6 프로시저
프로시저의 개요
- 절차형 SQL(연속적인 실행이나 분기 반복등의 제어가 가능한 SQL)을 활용하여 특정 기능을 수행하는 일종의 트랜잭션 언어로 호출을 통해 실행되어 미리 저장해놓은 SQL 작업을 수행함.
- 프로시저를 만들어 데이터베이스에 저장하면 여러 프로그램에서 호출하여 사용할 수 있음.
- 프로시저는 데이터베이스에 저장되어 수행되기 때문에 스토어드(Stored) 프로시저라고도 불림.
- 프로시저는 시스템의 일일 마감 작업, 일괄 작업 등에 주로 사용됨.
- 프로시저의 구성도

- DECLARE: 프로시저의 명칭, 변수, 인수, 데이터 타입을 정의하는 선언부
- BEGIN/END: 프로시저의 시작과 종료를 의미.
- CONTROL: 조건문 또는 반복문이 삽입되어 순차적으로 처리됨.
- SQL: DML, DCL이 삽입되어 데이터 관리를 위한 조회, 추가, 수정, 삭제 작업을 수행함.
- EXCEPTION: BEGIN ~ END 안의 구문 실행시 예외가 발생하면 이를 처리하는 방법을 정의함.
- TRANSACTION: 수행된 데이터 작업들을 DB에 적용할지 취소할지를 결정하는 처리부.
프로시저 생성
|
CREATE [OR REPLACE] PROCEDURE 프로시저명(파라미터 매개변수명 자료형) [지역변수 선언] BEGIN 프로시저 BODY; END; |
- OR REPLACE: 선택적 예약어. 동일한 프로시저 이름이 이미 존재하는 경우 기존의 프로시저를 대체할 수 있음.
- 파라미터
- IN: 호출 프로그램이 프로시저에게 값을 전달할 때 지정.
- OUT: 프로시저가 호출 프로그램에게 값을 반환할 때 지정.
- INOUT: 호출 프로그램이 프로시저에게 값을 전달하고, 프로시저 실행 후 호출 프로그램에 값을 반환할 때 지정.
- 매개변수 명: 호출프로그램으로부터 전달받은 값을 저장할 변수의 이름을 지정.
- 자료형: 변수의 자료형 지정.
- 프로시저 BODY
- 프로시저의 코드 기록하는 부분.
- BEGIN에서 시작하여 END로 끝나며, 적어도 하나의 SQL문이 있어야 함.
(예) 사원번호를 입력 받아 해당 사원의 ‘지급방식’을 “S”로 변경하는 프로시저를 생성하시오.
|
CREATE OR REPLACE PROCEDURE change_s(i_사원번호 IN INT) IS // 변수를 선언하는 예약어. 변수를 사용하지 않으므로 예약어만 입력. BEGIN UPDATE 급여 SET 지급방식 = ‘S’WHERE 사원번호 = i_사원번호; EXCEPTION WHEN PROGRAM_ERROR THEN ROLLBACK; COMMIT; END; |
프로시저 실행
|
EXECUTE 프로시저명(파라미터); EXEC 프로시저명(파라미터); CALL 프로시저명(파라미터); |
프로시저 제거
|
DROP PROCEDURE프로시저명; |
8.7 트리거
트리거의 개요
- 데이터베이스 시스템에서 데이터의 삽입, 갱신, 삭제 등의 이벤트가 발생할 때마다 관련 작업이 자동으로 수행되는 절차형 SQL.
- 트리거는 데이터베이스에 저장되며, 데이터 변경 및 무결성(데이터베이스에 정확하지 않은 데이터가 저장되는 것을 방지하는 제약조건) 유지, 로그 메시지 출력 등의 목적으로 사용됨.
- 트리거의 구문에는 DCL을 사용할 수 없으며, DCL이 포함된 프로시저나 함수를 호출하는 경우에도 오류가 발생.
- 트리거에 오류가 있는 경우 트리거가 처리하는 데이터에도 영향을 미치므로 트리거를 생성할 때 세심한 주의가 필요함.
트리거의 구성
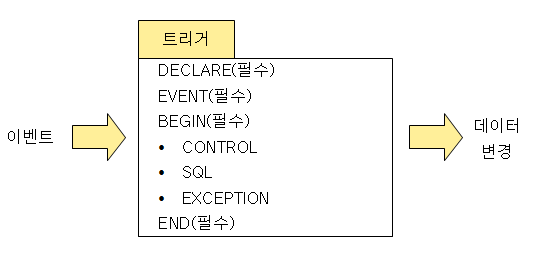
- DECLARE: 트리거의 명칭, 변수 및 상수, 데이터 타입을 정의하는 선언부.
- EVENT: 트리거가 실행되는 조건.
- BEGIN/END: 트리거의 시작과 종료.
- CONTROL: 조건문 또는 반복문이 삽입되어 순차적으로 처리.
- SQL: DML문이 삽입되어 데이터 관리를 위한 조회, 추가, 수정, 삭제 작업을 수행.
- EXCEPTION: BEGIN ~ END 안의 구문 실행 시 예외가 발생하면 이를 처리하는 방법을 정의.
트리거의 생성
|
CREATE [OR REPLACE] TRIGGER 트리거명 [동작시기 옵션][동작 옵션] ON 테이블명 REFERENCING [NEW | OLD] AS 테이블명 FOR EACH ROW [WHEN 조건식] BEGIN 트리거 BODY; END; |
- 동작 시기 옵션
- AFTER: 테이블이 변경 된 후 트리거 실행.
- BEFORE: 테이블이 변경되기 전 트리거 실행.
- 동작 옵션: INSERT, DELETE, UPDATE
- NEW | OLD: 트리거가 적용될 테이블의 별칭을 지정
- NEW: 추가되거나 수정에 참여할 테이블
- OLD: 수정되거나 삭제 전 테이블
- FOR EACH ROW: 각 튜플마다 트리거를 적용한다는 의미
- WHEN 조건식: 선택적인 예약어. 트리거를 적용할 튜플의 조건을 지정.
- 트리거 BODY: 적어도 하나 이상의 SQL문이 있어야 함.
(예) <학생> 테이블에 새로운 튜플이 삽입될 때, 삽입되는 튜플에 학년 정보가 누락됐으면 ‘학년’ 속성에 ‘신입생’을 저장하는 트리거를 ‘학년정보_tri’라는 이름으로 정의하시오.
|
CREATE OR REPLACE TRIGGER 학년정보_tri BEFORE INSERT ON 학생 REFERENCING NEW AS new_table FOR EACH ROW WHEN (new_table.학년 IS NULL) BEGIN :new_table.학년 := ‘신입생’; END; |
- :new_table NEW 또는 OLD 로 지정된 테이블 이름 앞에는 콜론이 들어감
- A := B A에 B를 저장하라는 의미
트리거의 제거
|
DROP TRIGGER 트리거명; |
8.8 사용자 정의 함수
사용자 정의 함수의 개요
- 프로시저와 유사하게 SQL을 사용하여 일련의 작업을 연속적으로 처리하며, 종료시 처리 결과를 단일값으로 반환하는 절차형 SQL.
- 사용자 정의 함수는 데이터베이스에 저장되어 SELECT, INSERT, DELETE, UPDATE 등 DML문의 호출에 의해 실행됨.
- 예약어 RETURN을 통해 값을 반환하기 때문에 출력 파라미터가 없음.
- INSERT, DELETE, UPDATE를 통한 테이블 조작은 할 수 없고 SELECT를 통한 조회만 할 수 있음.
- 사용자 정의 함수는 프로시저를 호출하여 사용할 수 없음.
- SUM(), AVG() 등의 내장함수처럼 DML문에서 반환 값을 활용하기 위한 용도로 사용됨.
|
구분 |
프로시저 |
사용자 정의 함수 |
|
반환값 |
없거나 1개 이상 가능 |
1개 |
|
파라미터 |
입, 출력 가능 |
입력만 가능 |
|
사용가능 명령문 |
DML, DCL |
SELECT |
|
호출 |
프로시저, 사용자 정의 함수 |
사용자 정의 함수 |
|
사용법 |
실행문 |
DML에 포함 |
사용자 정의 함수의 구성
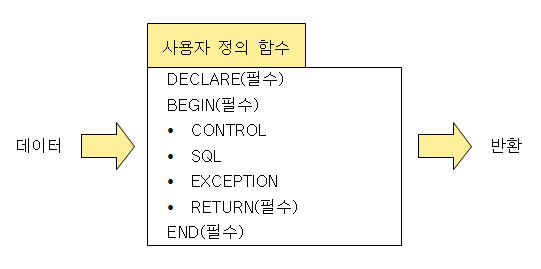
- RETURN: 호출 프로그램에 반환할 값이나 변수를 정의함.
사용자 정의 함수 생성
|
CREATE [OR REPLACE] FUNCTION 함수명(매개변수명 IN 자료형) [지역변수 선언] BEGIN 사용자정의함수 BODY; RETURN 반환값; END; |
(예) ‘i_성별코드’를 입력받아 1이면 ‘남자’, 2면 ‘여자’를 반환하는 사용자 정의함수 ‘Get_S’를 정의하시오
|
CREATE OR REPLACE FUNCTION Get_S(i_성별코드 IN INT) RETURN VARCHAR2 // 블록에서 리턴할 데이터의 자료형 정의. 자료형의 크기는 입력하지 않음. IS BEGIN IF i_성별코드 = 1 THEN RETURN ‘남자’; ELSE RETURN ‘여자’; ENDIF; // IF 문의 끝 END; |
사용자 정의 함수 실행
- 사용자 정의 함수는 DML에서 속성명이나 값이 놓일 자리를 대체하여 사용된다.
- 표기 형식
|
SELECT 함수명 FROM 테이블명; INSERT INTO 테이블명(속성명) VALUES(함수명); DELETE FROM 테이블명 WHERE 속성명 = 함수명; UPDATE 테이블명 SET 속성명 = 함수명; |
(예) <사원> 테이블을 출력하되, 성별코드는 ‘Get_S’ 함수에 값을 전달하여 반환받은 값으로 대체하여 출력하시오.
|
SELECT 이름, Get_S(성별코드) FROM 사원; |
사용자 정의 함수 제거
|
DROP FUNCTION 사용자정의함수명; |
8.9 제어문
제어문의 개요
- 절차형 SQL을 SQL 명령어가 서술된 순서에 따라 위에서 아래로 차례대로 실행되는데, 제어문은 이러한 진행 순서를 변형하기 위해 사용하는 명령문.
- 제어문 종류: IF, LOOP, GOTO 등
IF문
- 형식 1: 조건이 참일 때만 실행.
|
IF 조건 THEN 실행할 문장1; 실행할 문장2; ENDIF; |
- 형식 2: 조건이 참일 때와 거짓일 때 실행할 문장이 다름.
|
IF 조건 THEN 실행할 문장1; ELSE 실행할 문장2; ENDIF; |
- 형식 3: 조건이 여러개일 때 각 조건마다 실행할 문장이 다름.
|
IF 조건1 THEN 실행할 문장1; ELSEIF 조건2 THEN 실행할 문장2; ELSE 실행할 문장3; ENDIF; |
LOOP문
- 기본형: EXIT WHEN 조건이 참일 때 반복을 종료.
|
LOOP 실행할 문장1; EXIT WHEN 조건; END LOOP; |
(예) 1부터 10까지 합을 구하는 절차형 SQL을 구현.
|
DECLARE x INT := 1; sum INT := 0; BEGIN LOOP sum := sum + x; x := x +1; EXIT WHEN x >= 10; END LOOP; END; |
- FOR LOOP: 초기값부터 종료값까지 1씩 증가하면서 실행할 문장을 반복 수행.
|
FOR 변수 IN 초기값..종료값 LOOP 실행할 문장; END LOOP; |
(예) 1부터 10까지 구하는 절차형 SQL(FOR LOOP)
|
DECLARE sum INT := 0; BEGIN FOR i IN 1..10 LOOP sum := sum + i; END LOOP; END; |
- WHILE LOOP: 조건이 참인 동안 실행할 문장을 반복 수행.
|
WHILE 조건 실행할문장; END LOOP; |
(예) 1부터 10까지 합을 구하는 절차형 SQL(WHILE)
|
DECLARE i INT := 0; sum IN := 0; BEGIN WHILE i < 10 LOOP i := i + 1; sum := sum + i; END LOOP; END; |
CONTINUE
- 반복문의 실행을 제어하기 위해 사용되는 예약어.
- CONTINUE 이후의 문장은 실행하지 않고 제어를 반복문의 처음으로 옮김.
- 형식
|
CONTINUE WHEN 조건; |
(예) 화면에 ‘GILBUT’, ‘SINAGONG’ 반복 출력하는 절차형 SQL
|
BEGIN FOR i IN 1..3 LOOP DBMS_OUTPUT.PUT_LINE(‘GILBUT’); CONTINUE WHEN i=2; DBMS_OUTPUT.PUT_LINE(‘SINAGONG’); END LOOP; END; |
GOTO문
- 원하는 위치로 이동하여 명령문을 수행하기 위해 사용하는 제어문.
- 원하는 문장으로 쉽게 이동할 수 있지만 많이 사용하면 프로그램의 이해와 유지보수가 어려워져 거의 사용하지 않음.
- 형식
|
<<레이블>> GOTO 레이블; // 레이블로 이동 |
(예) 1부터 10까지 구하는 절차형 SQL(GOTO)
|
DECLARE i INT := 0; sum INT := 0; BEGIN <<rec>> i := i + 1; sum := sum + i; IF i < 10 THEN GOTO rec; ENDIF; END; |
8.10 커서
커서의 개념
- 쿼리문의 처리 결과가 저장되어있는 메모리 공간을 가리키는 포인터.
- 커서의 수행은 열기, 패치, 닫기 의 세단계로 진행됨.
|
묵시적 커서 |
명시적 커서 |
|
내부에서 자동으로 생성되어 사용. |
사용자가 직접 정의해서 씀. |
|
각 단계가 자동으로 수행 |
각 단계를 직접 구현해야 함. |
|
수행된 쿼리문의 정상 수행 여부를 확인하기 위해 사용. |
쿼리문의 결과를 저장하여 사용함으로써 동일한 쿼리가 반복 수행되어 데이터베이스 자원이 낭비되는 것을 방지함. |
묵시적 커서
- DBMS 자체적으로 열리고, 패치되어 사용이 끝나면 닫히지만 커서의 속성을 조회하여 사용된 쿼리 정보를 열람하는 것이 가능함.
- 커서의 속성
- SQL%FOUND: 쿼리 수행 결과로 패치된 튜플 수가 1개 이상이면 TRUE
- SQL%NOTFOUND: 쿼리 수행 결과로 패치된 튜플수가 0개면 TRUE
- SQL%ROWCOUNT: 쿼리 수행 결과로 패치된 튜플 수를 반환.
- SQL%ISOPEN: 커서가 열린 상태면 TRUE. 묵시적 커서는 자동으로 생성되고 자동으로 닫히기 때문에 항상 FALSE
(예) <SCORE> 테이블에서 UPDATE를 수행하고 갱신된 튜플의 수를 확인하는 절차형 SQL
|
BEGIN UPDATE SCORE SET COND = 25 WHERE DEPT = ‘PR’; DBMS_OUTPUT.PUT_LINE(SQL%ROWCOUNT); END; |
명시적 커서
- 사용자가 직접 정의해서 사용하는 커서. 주로 절차형 SQL에서 SELECT문의 결과로 반환되는 여러 튜플들을 제어하기 위해 사용됨.
- 커서는 기본적으로 열기 - 패치 - 닫기 순으로 이루어지며, 명시적 커서로 사용하기 위해서는 열기 전에 선언을 해야 함.
- 선언 형식
|
CURSOR 커서명(매개변수1, 매개변수2, …) IS SELECT문; // 커서가 오픈될 때 수행할 SELECT 문을 작성함. 커서는 SELECT문의 실행 결과가 저장된 곳의 시작 위치를 가리킴. |
- 열기 형식
|
OPEN 커서명(매개변수1, 매개변수2, …); |
- 패치 형식
|
FETCH 커서명 INTO 변수1, 변수2, …; // 커서에 저장된 튜플들의 각 속성과 같은 자료형을 가진 변수를 적고 데이터를 가져옴. |
- 닫기 형식
|
CLOSE 커서명; // 사용된 커서는 메모리 해제를 위해 반드시 닫아야 함 |
(예) <employee> 테이블로부터 id가 20보다 크거나 같은 튜플의 name을 출력하는 절차형 SQL
|
DECLARE p_name employee.name%TYPE; // name의 속성의 자료형과 동일한 변수 선언. // 선언 CURSOR cur_name(ff INT) IS SELECT name FROM employee WHERE id >= ff; BEGIN // 오픈 OPEN cur_name(20); LOOP // 패치 FETCH cur_name INTO p_name; EXIT WHEN cur_name%NOTFOUND; DBMS_OUPPUT.PUT_LINE(p_name); END LOOP; // 종료 CLOSE cur_name; END; |
'2021 정보처리기사 > 실기 요약' 카테고리의 다른 글
| [정보처리기사 실기] 10장 요약 _ 응용 SW 기초 기술 활용 (1) | 2021.04.22 |
|---|---|
| [정보처리기사 실기] 9장 요약 키워드 정리 _ 소프트웨어 개발 보안 구축 (0) | 2021.04.17 |
| [정보처리기사 실기] 7장 요약 키워드 정리 _ 애플리케이션 테스트 관리 (0) | 2021.04.14 |
| [정보처리기사 실기] 6장 요약 키워드 정리 _ 화면 설계 (0) | 2021.04.10 |
| [정보처리기사 실기] 5장 요약 키워드 정리 _ 서버 프로그램 구현 (0) | 2021.04.08 |





